TiDB 中的子查询优化技术
-
 Mon, Aug 1, 2016
Mon, Aug 1, 2016 -
 韩飞
韩飞
子查询简介
子查询是嵌套在另一个查询中的 SQL 表达式,比较常见的是嵌套在 FROM 子句中,如
SELECT ID FROM (SELECT * FROM SRC) AS T。对于出现在 FROM 中的子表达式,一般的 SQL 优化器都会处理的很好。但是当子查询出现在 WHERE 子句或 SELECT 列表中时,优化的难度就会大大增加,因为这时子查询可以出现在表达式中的任何位置,如 CASE...WHEN... 子句等。
对于不在 FROM 子句出现的子查询,分为“关联子查询”(Correlated Subquery) 和“非关联子查询”。关联子查询是指子查询中存在外部引用的列,例如:
SELECT * FROM SRC WHERE
EXISTS(SELECT * FROM TMP WHERE TMP.id = SRC.id)对于非关联子查询,我们可以在 plan 阶段进行预处理,将其改写成一个常量。因此,本文只考虑关联子查询的优化。
一般来说,子查询语句分为三种:
标量子查询(Scalar Subquery),如(SELECT…) + (SELECT…)
集合比较(Quantified Comparision),如T.a = ANY(SELECT…)
存在性测试(Existential Test),如NOT EXISTS(SELECT…),T.a IN (SELECT…)
对于简单的存在性测试类的子查询,一般的做法是将其改写成 SEMI-JOIN。但是很少有文献给出通用性的算法,指出什么样的查询可以“去关联化”。对于不能去关联化的子查询,数据库的做法通常是使用类似 Nested Loop 的方式去执行,称为 correlated execution。
TiDB 沿袭了 SQL Server 对子查询的处理思想,引入 Apply 算子将子查询用代数形式表示,称为归一化,再根据 Cost 信息,进行去关联化。
Apply 算子
子查询难以优化的原因是,人们通常不能把一个子查询执行表示成一个类似 Projection、Join 这样的逻辑算子。这使得找到一个通用子查询转换的算法是很难的。所以我们第一件要做的事就是,引入一个可以表示子查询的逻辑算子:Apply。
Apply 算子的语义是:
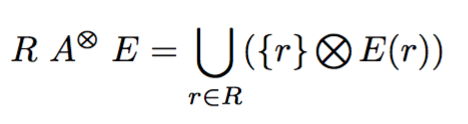
公式中的 E 代表一个“参数化”的子查询。在每一次执行中,Apply 算子会向关系 R 取一条记录 r,作为参数传入 E 中,然后让 r 和 E® 做 ⊗ 操作。⊗ 会根据子查询类型的不同而不同,通常是半连接 ⋉。
对于 SQL 语句:
SELECT * FROM SRC WHERE
EXISTS(SELECT * FROM TMP WHERE TMP.id = SRC.id)它的 Apply 算子表示是:
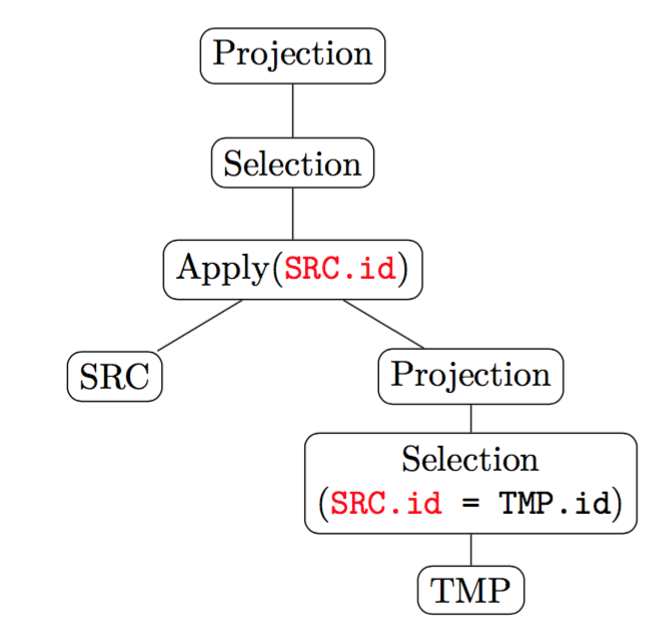
对于出现在 SELECT 列表中、GROUP BY 列表中的子查询,道理也是类似的。所以 Apply 是可以表示出现在任意位置的子查询的。
去关联化
引入了 Apply,我们就可以将子查询去关联化了。去关联化的规则如下:

根据上述规则,你可以将所有的确定性 SQL 子查询去关联化。例如 SQL 语句:
SELECT C_CUSTKEY
FROM CUSTOMER WHERE 1000000 <
(SELECT SUM(O_TOTALPRICE)
FROM ORDER WHERE O_CUSTKEY = C_CUSTKEY)其中两个 CUSTKEY 均为主键。转换成 Apply 之后的表达式为:
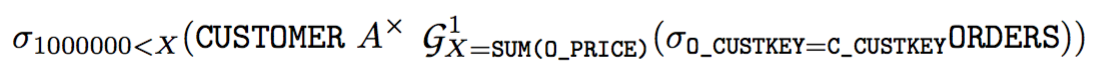
因为主键的存在,利用规则(9),可以转化为:

此时根据规则(2),我们可以彻底消除 Apply,转化为只有连接的 SQL 表达式:

再根据外连接化简的原则,可以进一步化简为:
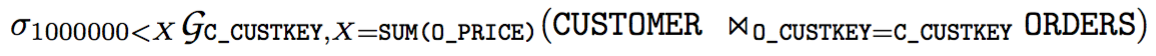
利用上述九条规则,理论上已经解决去关联化的问题了。是不是对于所有的情况,去关联化都是最好的呢?答案是否定的。如果 SQL 的结果很小,同时子查询可以利用索引,有时候使用 correlated execution 是最好的。是否去关联化还需要统计信息的帮助。而到了这一步,普通的优化器已经无能为力了。只有 Volcano 或 Cascade Style 的优化器,可以同时考虑逻辑等价规则和代价选择。因此,想要完美解决子查询的问题,要需要优秀的优化器框架的支撑。
半连接
TiDB 在去关联化方面,目前只支持将关联子查询改写成半连接和左外半连接。例如,对于查询:
SELECT * FROM SRC WHERE
EXISTS(SELECT * FROM TMP WHERE TMP.id = SRC.id)TiDB 做出的 Plan 为:
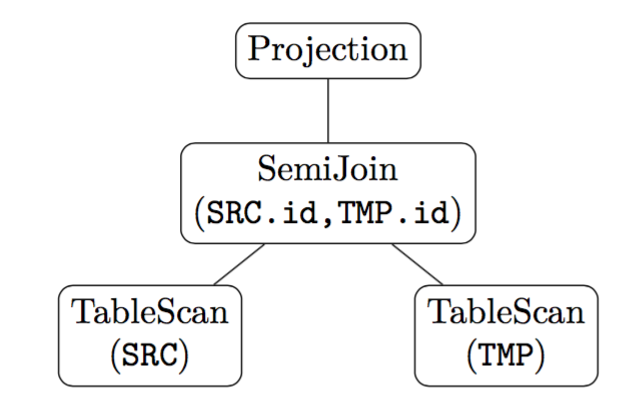
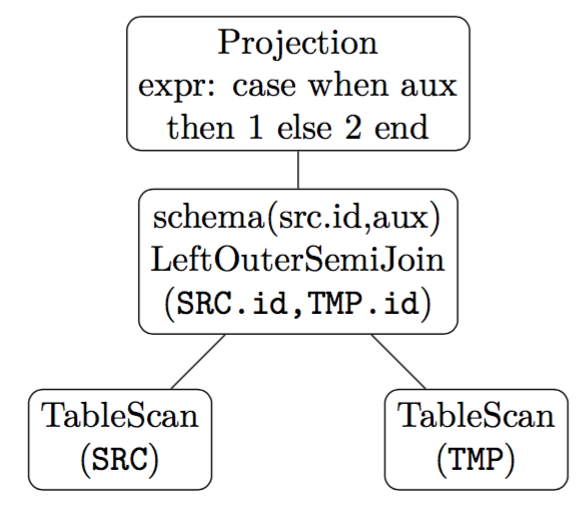
当子查询出现在 SELECT 子句当中时:
SELECT CASE WHEN
EXISTS(SELECT * FROM TMP WHERE TMP.id = SRC.id)
THEN 1 ELSE 2 END FROM SRCProjection 算子需要知道 Exists 结果是 True 或者 False。这时需要左外半连接,当然外表匹配时,有一个辅助列 aux 输出 True,当不匹配时,输出 False。
对于半连接的算法实现,其实和 Join 差别不大,可以选择 MergeSortJoin,HashJoin,IndexLoopUpJoin,NestedLoop 等等。确定使用 SemiJoin 之后,优化器会根据统计信息选择最合适的算法,这里不再赘述。