演讲实录|黄东旭:Cloud-Native 的分布式数据库架构与实践
-
 Sat, Apr 22, 2017
Sat, Apr 22, 2017 -
 黄东旭
黄东旭
4 月 19 日,我司 CTO 黄东旭同学在全球云计算开源大会上,发表了《Cloud-Native 的分布式数据库架构与实践》主题演讲,以下为演讲实录。
实录

大家好,今天我的题目是 Cloud-Native 与分布式数据库的实践。先简单的介绍一下自己,我是 PingCAP 的联合创始人和 CTO,过去一直在做基础软件领域的工程师,基本上做的所有的东西都是开源。在分享之前我想说一下为什么现在各行各业或者整个技术软件社区一直在重复的再造数据库,现在数据库到底怎么了,为什么这么百花齐放?
首先随着业务的多种多样,还有不管是传统行业还是互联网行业,业务的迭代速度越来越互联网化,使得整个数据量其实是一直在往上走的;
第二就是随着 IOT 的设备还有包括像手机、移动互联网蓬勃的发展,终端其实也不再仅仅是传统的 PC 客户端的数据的接入;
第三方面随着现在 AI 或者大数据分析一些模型或者理论上的突破,使得在大数据上进行计算的手段越来越多样,还有在物理上一些硬件的新的带有保护的内存,各种各样新的物理的设备,越来越多的硬件或者物理上的存储成本持续的降低,使得我们的数据库需要要面对更多的挑战。
关联数据库理论是上世纪七十年代做出来的东西,现在四十年过去不管是物理的环境还是计算模型都是完全不一样的阶段,还抱着过去这种观念可能并不是一个面向未来的设计。而且今天我的题目是 Cloud-Native,有一个比较大胆的假设,大家在过去三十年的计算平台基本都是在一台 PC 或者一个服务器或者一个手机这样的独立的计算平台,但是未来我觉得一切的服务都应该是分布式的。因为我觉得摩尔定律已经失效了,所以未来的操作系统会是一个大规模分布式的操作系统,在上面跑的任何的进程,任何的服务都应该是分布式的,在这个假设下怎么去做设计,云其实是这个假设最好的载体。怎么在这个假设上去设计面向云的技术软件,其实是最近我一直在思考的一个问题。其实在这个时代包括面向云的软件,对业务开发来说尽量还是不要太多的改变过去的开发习惯。你看最近大数据的发展趋势,从最传统的关系数据库到过去十年相比,整个改变了用户的编程模型,但是改变到底是好的还是不好的,我个人觉得其实并不是太好。最近这两年大家会看到整个学术圈各种各样的论文都在回归,包括 DB 新时代的软件都会把扩展性和分布式放在第一个要素。
大家可能听到主题会有点蒙,叫 Cloud-Native,Cloud-Native 是什么?其实很早的过去也不是没有人做过这种分布式系统的尝试,最早是 IBM 提出面向服务的软件架构设计,最近热门的 SOA、Micro Service 把自己的服务拆分成小的服务,到现在谷歌一直对外输出一个观点就是 Cloud-Native,就是未来大家的业务看上去的分布式会变成一个更加透明的概念,就是你怎么让分布式的复杂性消失在云的基础设施后,这是 Cloud-Native 更加关心的事情。
这个图是 CNCF 的一个基金会,也是谷歌支持的基金会上扒过来的图。这里面有一个简单的定义,就是 SCALE 作为一等公民,面向 Cloud-Native 的业务必须是弹性伸缩的,不仅能伸也得能缩;第二就是在对于这种 Cloud-Native 业务来说是面向 Micro service 友好;第三就是部署更加的去人工化。
最近大家可能也看到很多各种各样容器化的方案,背后代表的意义是什么?就是整个运维和部署脱离人工,大家可以想象过去十几二十年来,一直以来运维的手段是什么样的。我找了一个运维,去买服务器,买服务器装系统,在上面部署业务。但是现在 Cloud-Native 出现变得非常的自动化,就相当于把人的功能变得更低,这是很有意义的,因为理想中的世界或者未来的世界应该怎么样,一个业务可能会有成百上千的物理节点,如果是人工的去做运维和部署是根本不可能做得到的,所以其实构建整个 Cloud-Native 的基础设施的两个条件:第一个就是存储本身的云化;第二就是运维要和部署的方式必须是云化的。
我就从这两个点说一下我们 TiDB 在上面的一些工作和一些我的思考。
存储本身的云化有几个基本条件,大家过去认为是高可用,主要停留在双活。其实仔细去思考的话,主备的方案是很难保证数据在完全不需要人工的介入情况下数据的一致性可用性的,所以大家会发现最近这几年出来的分布式存储系统的可用性的协议跟复制协议基本都会用类似 Raft/Paxos 基于选取的一致性算法,不会像过去做这种老的复制的方案。
第二就是整个分片的策略,作为分布式系统数据一定是会分片的,数据分片是来做分布式存储唯一的思路,自动分片一定会取代传统的人工分片来去支撑业务。比如传统分片,当你的数据量越来越大,你只能做分库分表或者用中间件,不管你分库分表还是中间件都必须制订自己人工的分辨规则,但是其实在一个真正面向 Cloud 的数据库设计里,任何一种人的介入的东西都是不对的。
第三,接入层的去状态化,因为你需要面对 Cloud-Native 做设计,你的接入层就不能带有状态,你可以相当于是前端的接入层是一层无状态的或者连接到任何一个服务的接入的入口,对你来说应该都是一样的,就是说你不能整个系统因为一个关键组件的损坏或者说磁盘坏掉或者机器的宕机,整个系统就不能服务了,整个测试系统应该具有自我愈合和自我维护的能力。 其实我本身是架构师,所以整个我们数据库的设计都是围绕这些点来做思考的,就是一个数据库怎么能让他自我的生长,自我的维护,哪怕出现任何的灾难性的物理故障(有物理故障是非常正常的,每天在一个比较大的集群的规模下,网络中断、磁盘损坏甚至是很多很诡异的问题都是很正常的),所以怎么设计这种数据库。
我们的项目是 TiDB,我不知道在座的有没有听说过这个项目,它其实是一个开源实现。当你的业务已经用了数据库,数据量一大就有可能遇到一些问题,一个是单点的可靠性的问题,还有一个数据容量怎么去弹性伸缩的问题。TiDB 就能解决这个问题,它本身对外暴露了一个接口,你可以用客户端去连接,你可以认为你下面面对的是一个弹性动态伸缩完全没有容量限制,同时还可以在上面支持复杂的子查询的东西。底层存储的话,相当于这一层无状态的会把这个请求发到底层的节点上,这个存储里面的数据都是通过协议做高可用和复制的,这个数据在底层会不停的分裂和移动,你可以认为这个数据库是一个活的数据库,你任何一个节点的宕机都不会影响整个数据库对业务层的使用,包括你可以跨数据中心部署,甚至你在跨数据中心的时候,整个数据中心网络被切断,机房着火,业务层都几乎完全是透明的,而且这个数据比如副本丢失会自己去修复,自己去管理或者移动数据。
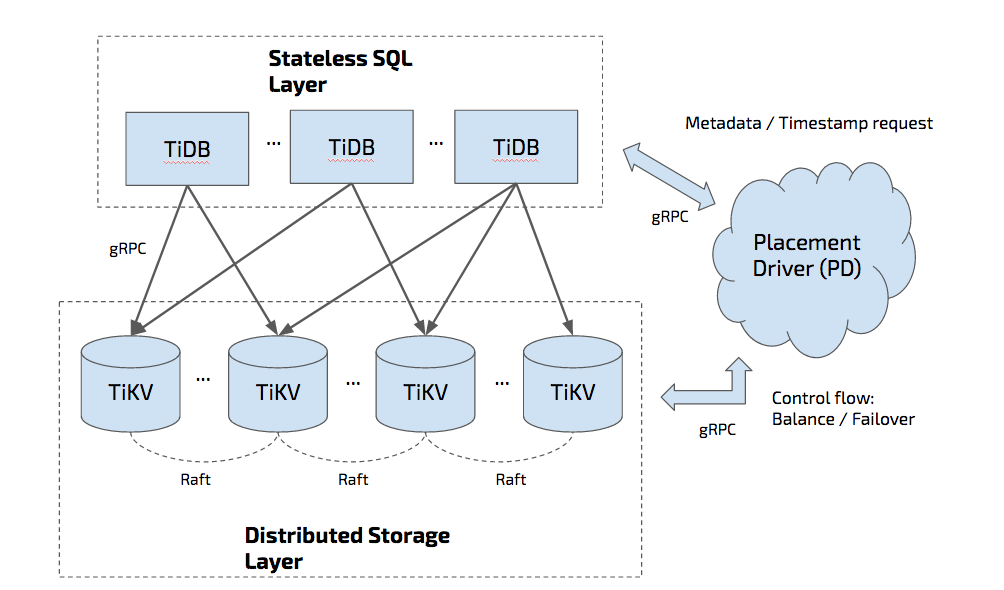
上图右边是一个集群的调度模块,你可以认为它是整个集群的大脑,是一个 7×24 小时不眠的 DBA,你任何的业务可以接上来。NewSQL 这个词大家听的都烂了,但是我还是想提,首先它是一个面向扩展的数据库,同时它还结合的传统管理数据库的强一致事务,必须得是 SSI 隔离级别的,并不是非常弱根本没法用的隔离级别,而是需要提供最强一致性的隔离级别的数据库。扩展性其实是通过在 TiKV 层面做完全自动分片,可用性是通过 Raft 为保证,我们整个数据库没有主从的概念,每一个节点既可以是主又可以是从,然后整个数据复制通过 Raft 为保证,对外的是一个强一致性的事务层,其实背后的算法是用两阶段提交的算法,比如一个最简单的例子,我一百个并发过来很快,每个平均十毫秒访问数据,一百个并发,一百万个并发,你还能保证每一个请求都是十毫秒返回数据吗?那我可以简单的通过添加机器把系统的吞吐加上去,每一个吞吐的响应延迟会更大一些,在论文里提到过,谷歌数据库写的每一个平均延迟是 150 到 100 毫秒,可以做到线性扩展。所以终于有一个数据库可以 scable。刚才说的是存储层面的云化,刚才提到了 Cloud-Native 还有一个重要的点就是部署和运维方式的云化,我们其实选的这个 Kubernetes 就是用来承载背后数据库大规模集群上的部署,其实大家都知道这个是什么东西,这是最出名的开源项目之一,谷歌开源的,大家也知道 borg,就是他们用了这么多年的集群调度服务,主要做的事情就是服务的编排、部署、自动化的运维,一台物理机挂掉了,他会很好的让这个业务不中断,像集群调度器,它就是整个数据中心的操作系统,但是面临最大的问题就是所有的业务一旦是有状态的,那你这个就非常恶心。举个案例,比如我在跑一个数据库,如果你这台物理机宕机,按照 Kubernetes 会开一个服务器在那边展开,但是这一台老的宕机服务器数据是存在上面的,你不能只是把进程在新的服务器那启起来而数据不带过去,相当于这种业务是带状态的,这在 Kubernetes 过去是一个老大难的问题,其实整个应用层,因为它的特性被分成了四个大的阵营,如果想上可以看一下自己的业务到底属于哪一个阵营。
第一个就是完全无状态的业务,比如这是一个简单的 CRUD 业务层的逻辑,其实是无状态的应用层。第二种就是单点的带状态的 applications,还有任何单机的数据库其实都有属于 applications。第三个就是 Static distributed,比如高可用的分布式服务,大家也不会做扩容什么的,这种是静态的分布式应用。还有最难的一个问题,就是这种集群型的 applications,clustered 是没有办法很好的调度服务的。这是刚才说的,其实对于 Single point,其实是很好解决的,对于静态的其实也是用 Static distributed 来解决带状态的持续化的方案。
刚才我说最难的那个问题,我们整个架构中引入了 Operational,调度一套有状态服务的方案,其实它思路也很简单,就是把运维分布人员系统的领域知识给嵌入到了系统中,Knowledge 发布调度任务之前都会相当于被 CoreOS 提供的接口以后再调度业务,这套方案依赖了 HtirdPartyResources 调度,因为这个里面我的状态我自己才知道,这个时候你需要通过把你的系统领域知识放到 operator 里。很简单,就是 Create 用 TiDB Operator 来实现,还有 Rollingupdate 和 Scale Out 还有 Failover 等。使用 Kubemetes 很重要的原因就是它只用到了很毛的一层 API,内部大量的逻辑是在 Operator 内部,而且像 PV/Statefulset 中并不是一个很好的方案,比如 PV 实现你可以用分布式文件系统或者快存储作为你持久化的这一层,但是数据库的业务,我对我底层的 IO 或者硬件有很强的掌控力的,我在我的业务层自己做了三副本和高可用,我其实就不需要在存储层面上比如我在一个裸盘上跑的性能能比其他上快十倍,这个时候你告诉我不好意思下面只支持 statefulset 那这是不适合跑数据库的,也就是数据库集群是跟它的普通的云盘或者云存储的业务是分开的。
分布式数据库也不是百分之百所有的业务场景都适合,特别是大规模的分布式数据库来说,比如自增 ID,虽然我们支持,但是自增 IT 高压力写入的时候它的压力会集中在表的末尾,其实是我不管怎么调度总会有一块热点,当然你可以先分表,最后我们聚合分析也没有问题,像秒杀或者特别小的表,其实是完全不适合在这种分布式数据库上做的,比较好的一些实践业务的读写比较平均,数据量比较大,同时还有并发的事务的支持,需要有事务的支持,但并不是冲突特别大的场景,并不是秒杀的场景,同时你又可以需要在上面做比较复杂的分析,比如现在我们的一些线上的用户特别好玩,过去它的业务全都是跑在 MySQL 上,一主多从,他发现我一个个 MySQL 成为了信息的孤岛,他并没有办法做聚合地分析,过去传统的方案就是我把 MySQL 或者数据通过一个 ETL 流程导到数据仓库里,但是开发者不会用各种琳琅满目大数据的东西,他只会用 MySQL,一般他做的数据分析都会把 MySQL 倒腾到一个库上再做分析,数据量一大堆分析不出来,这个时候他把所有他自己的 MySQL 总库连到了一个 TiDB上,过去是一主多从,先多主多从,把所有的从都打通,做 MySQL 的分析,所以我觉得 TiDB 打造了新的模型,可以读写高并发的事务,所以未来的数据库会是一个什么样子的,我觉得可能是至少我们觉得沿着这条路走下去应该会有一条新的路,谢谢大家。