Ele.me? TiDB At Your Service
-
 Fri, Jun 29, 2018
Fri, Jun 29, 2018 -
 PingCAP
PingCAP
Industry: Food Delivery
Authors: Yanzhao Zhang (Senior Database Engineer at Ele.me) and Dongming Chen (Senior Infrastructure Engineer at Ele.me)
Ele.me, which means “Are you hungry?” in Chinese, is the largest online food delivery platform in China. Our platform allows users to order all kinds of food and beverages and get their takeout delivered within 30 minutes. Currently, with 3 million scooter-riding delivery staff, Ele.me is serving 260 million customers and 1.3 million vendors in over 2,000 cities in China. In April 2018, Ele.me was acquired by Alibaba for $9.5 billion USD.
With a fast-growing business comes soaring data size, which has placed tremendous pressure on Ele.me’s backend system, especially the database. How to tackle the challenges that come with mounting data has been a nightmare until we found TiDB, a MySQL compatible distributed hybrid transactional and analytical processing (HTAP) database, and its distributed key-value storage engine TiKV, both built and supported by PingCAP. Finally, we can harness the power of our data and not be intimidated by it.
Currently, our TiKV deployment serves 80% of the traffic on the entire Ele.me platform, covering every activity from making orders to processing delivery. Our TiDB deployment holds 45% of our entire archived data. In this post, we will share how and why we chose TiDB and TiKV, how we are using them, best practice suggestions, and our experience in working hand-in-hand with the PingCAP team.
Our Evaluation Process
Before choosing TiDB/TiKV, we carefully evaluated other options – TokuDB, MySQL Cluster, Percona XtraDB Cluster, Cassandra, Vertica, Apache HBase, and Google Spanner. Here’s what we found:
TokuDB, a storage engine for MySQL and MariaDB, supports safe and fast DDL as a plug-in of MySQL. Applications which run on MySQL can work on TokuDB quite easily, but it is only a plug-in storage engine without elastic scalability.
MySQL Cluster and Percona XtraDB Cluster are scalable but only in their computing capability, not storage capacity. DDL for big tables also remains a tough task.
Column-oriented databases like Cassandra and Vertica support elastic scalability of both computing and storage with safe and fast DDL, but Cassandra is a non-relational database and does not support distributed transactions while Vertica is not designed for OLTP workloads. All of our existing MySQL-based applications must be transformed to be compatible with them, which creates a lot of work.
HBase has the same advantages and disadvantages of column-oriented databases. In addition, its operation and maintenance costs is too high for our archive job.
Google Spanner is a relational database which supports horizontal scalability, fast online DDL, and distributed transactions. But it does not support MySQL protocol and is only available on Google Cloud Platform.
Why TiDB and TiKV?
TiDB and TiKV support fast online DDL, horizontal scalability, and high availability by applying the Raft consensus protocol. It is also compatible with MySQL. TiDB presents a layered, modular architecture and allows us to use different components flexibly to meet our needs. Additionally, TiDB has an active open source community (more than 16,000 Github stars total), which gives us a lot of confidence in its pace of development, bug fixes, and future features.
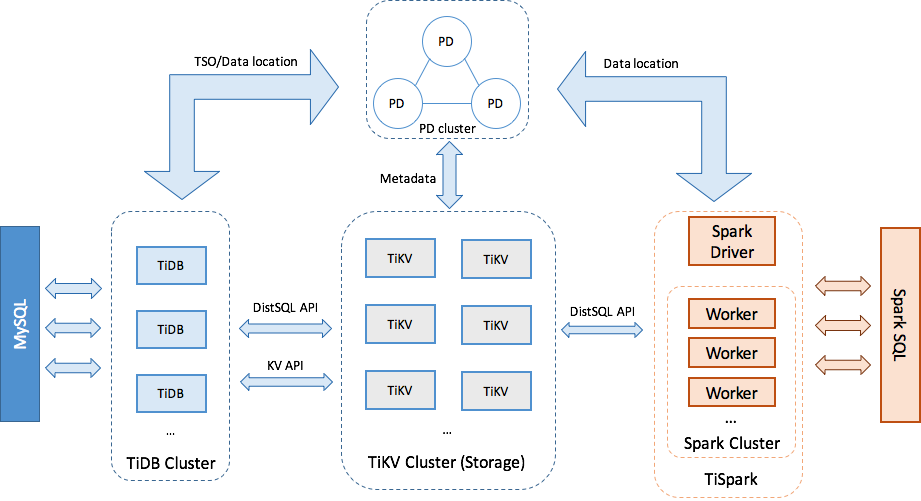
Use Case 1: Unifying Data Storage in TiKV
Most of our data is in key-value structure. Before using TiKV, our data was scattered among different databases, including MySQL, Redis, MongoDB, and Cassandra, making it very hard to scale, manage, and operate, not to mention overall poor performance. We needed a unified key-value storage system with the following technical criteria:
Large capacity to store at least dozens of TBs of data;
High QPS performance with low latency;
High availability and fault-tolerance. Data must be stored persistently and safely even with machine downtime. (The food delivery business demands higher real time data processing capability and availability compared with traditional E-commerce services, especially during peak hours.)
Easy operation and maintenance, with simple data migration and cluster scaling without interruption.
Redis on TiKV
TiKV, as a standalone component of the TiDB platform, meets all of our criteria, and can serve as a building block for other client protocols. We’ve been using Redis and wanted to keep using it with TiKV.
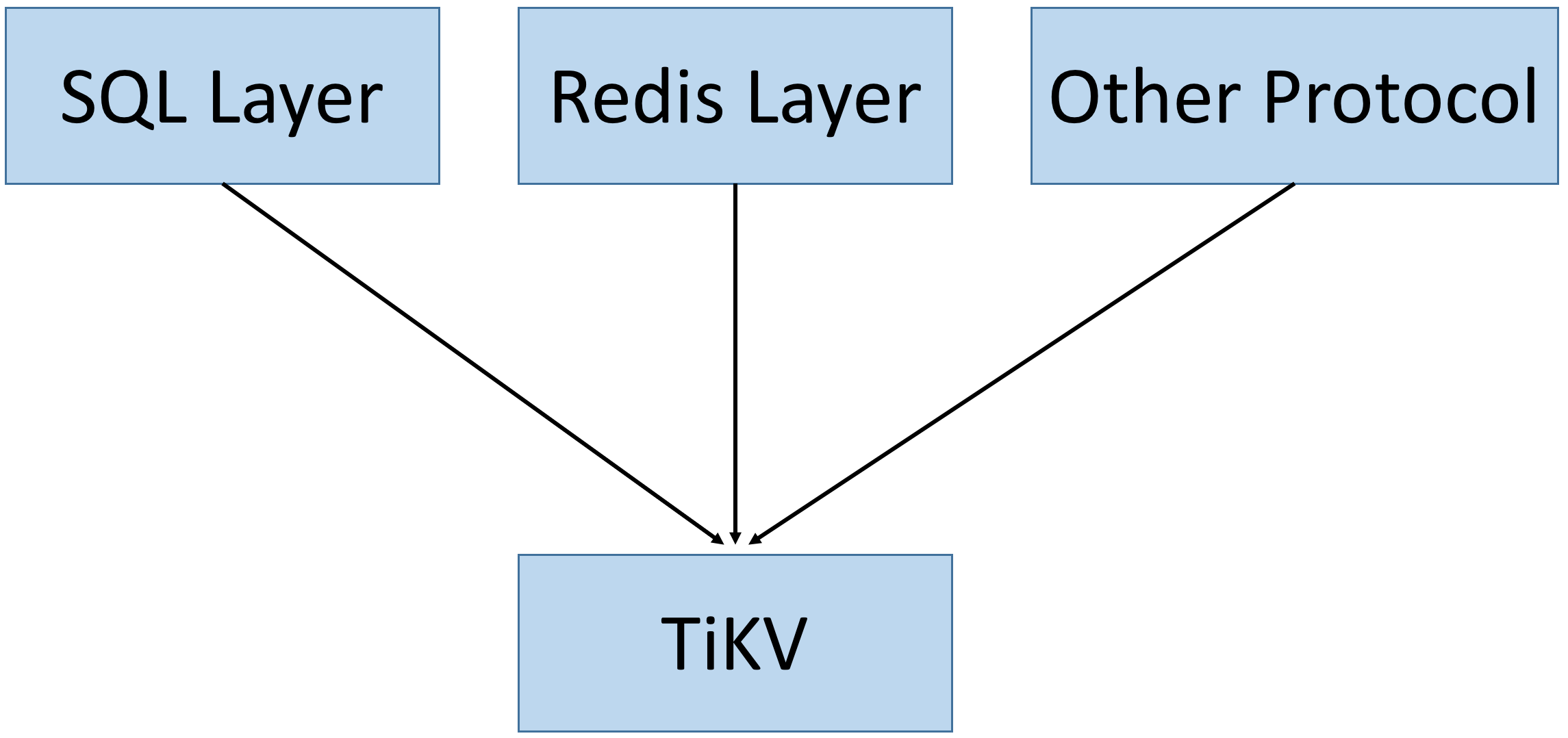
In this architecture, the upper layer translates the Redis protocol, while the TiKV layer implements distributed system features, including horizontal scalability, high availability and strong consistency using data partition, the Raft protocol, MVCC and distributed transaction.

With these components working together, we were able to build our own Redis proxy on top of TiKV, so we can tap into its power while keeping the interface we like to use best.
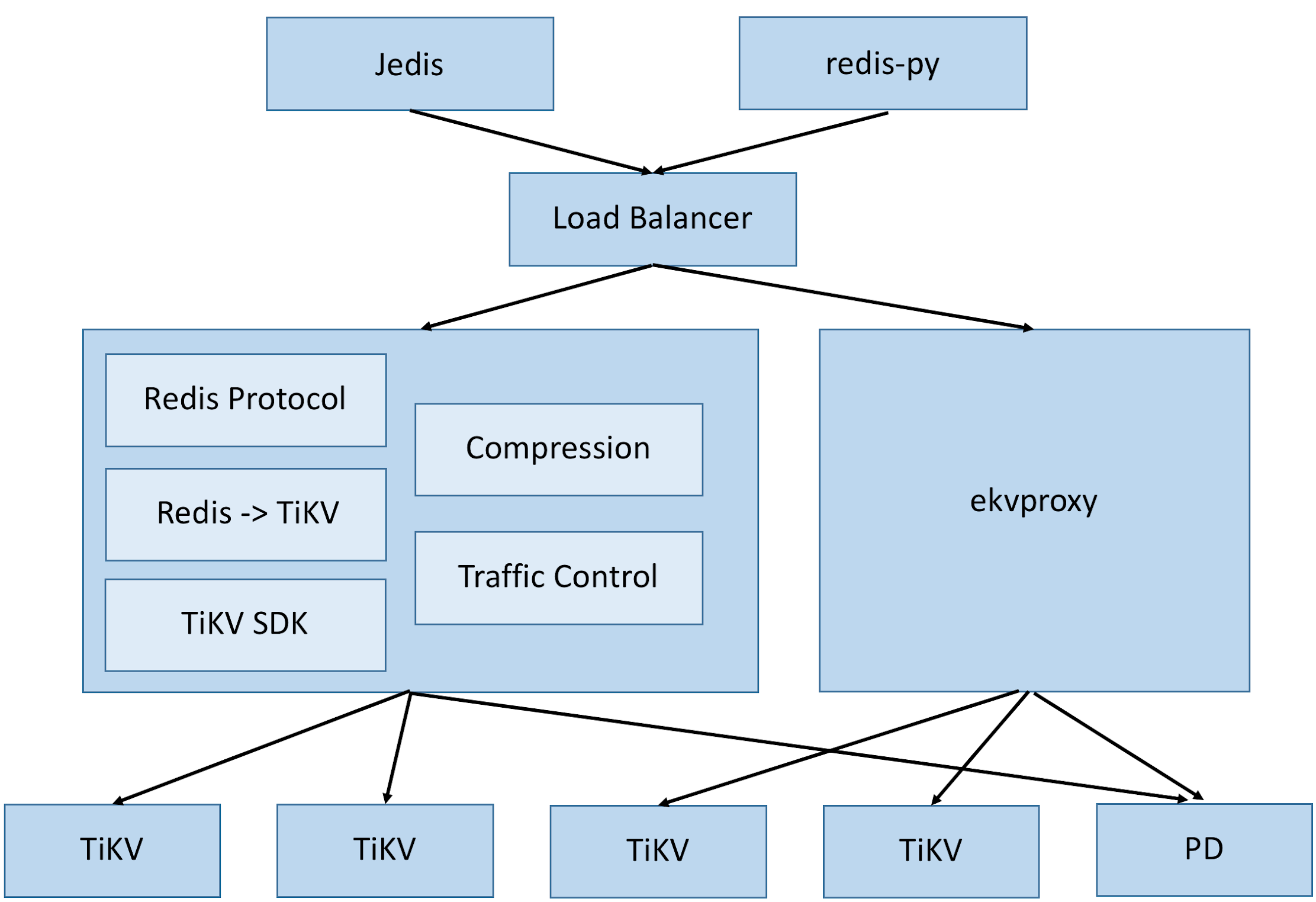
We built the ekvproxy service, where we wrapped the TiKV SDK to parse the Redis protocol and transformed it to communicate with TiKV. Extensions like compression and traffic control were implemented on this foundation. Our team can now use the official Redis client to access our key-value service backed by TiKV without changing their workflow or behavior.
The PingCAP team was instrumental in helping us implement the Raw SCAN feature of TiKV, so our service can be better compatible with the Redis protocol.
In-Production Scale
In the second half of 2017, we deployed TiKV as Ele.me’s main key-value storage system, which supports 80% of our traffic. The scale and status of our deployment is as follow:
A dozen TiKV clusters in four data centers located in Beijing, Shanghai and Guangzhou with 100+ nodes holding dozens of TBs of data;
A complete monitor alert system which all TiKV clusters connect to. It sends the alert messages instantly when problems occur, guaranteeing timely troubleshooting;
During peak traffic time, the Write QPS is nearly 50,000 and the Read QPS is approximately 100,000 in the busiest clusters;
We’ve deployed TiKV for almost a year, and thus far, all clusters have been running smoothly without any incident.
Use Case 2: TiDB As Archive
As our business continues to grow, so does our data volume, which constantly consumes more physical resources like disks and CPUs and affects performance.
To fix this, we often archive data on a regular basis from online services to offline storage. Some of our online services only need data from the last three weeks or three months.
Our Pain Points
MySQL is our main database solution at Ele.me for archiving. To archive a large amount of data, we deployed several highly available master-slave MySQL clusters on machines with large disk capacity. During the archiving process, we confronted three pain points:
Pain Point 1: Changing the table schema was a thorny task, and we needed DDL support. A standard archive process works well, when the data size increases gently and the table schema is fixed. But for Ele.me, the data volume is massive, grows quickly, and our services are constantly changing, which requires frequent modifications to the table schema.
Pain Point 2: Scaling the storage capacity horizontally was difficult. MySQL does not scale easily, and we keep on adding large disks but run out of room quickly. We had to constantly create new archive clusters, posing risks to our applications that need access to the archive from time to time.
Pain Point 3: It was time-consuming to resynchronize data after a failure recovery. Although the archive cluster was highly available, recovering from a master switch from unexpected downtime took a long time because of the nature of a master-slave architecture.
Thankfully, TiDB has the right features and design to provide online DDL, simple horizontal scalability, and Raft-based auto-recovery and self-healing, to help us solve all three pain points.
Adoption Process
Proof of Concept Setup
Initially during our trial of TiDB, we used 12 SATA disks. On each disk, we deployed an instance to increase the available space of the whole cluster. 36 TiKV instances for test were deployed on 3 physical machines; 3 TiDB instances and 3 Placement Driver (PD) instances shared another 3 physical machines. This was not the recommended way to deploy TiDB, so unsurprisingly, the performance was not great.The default parameters of TiDB are only optimized for SSD storage.
To solve this problem, we bundled these disks to be one disk via RAID 10, decreased the number of TiKV instances on a single physical machine from 12 to 3, and increased the block cache size. Considering the high performance of CPU, we improved the default compression level of TiKV to reduce the scheduling data size as much as possible. We also tested the scaling-in and scaling-out features, online DDL, and high availability of TiDB, which all met our requirements.
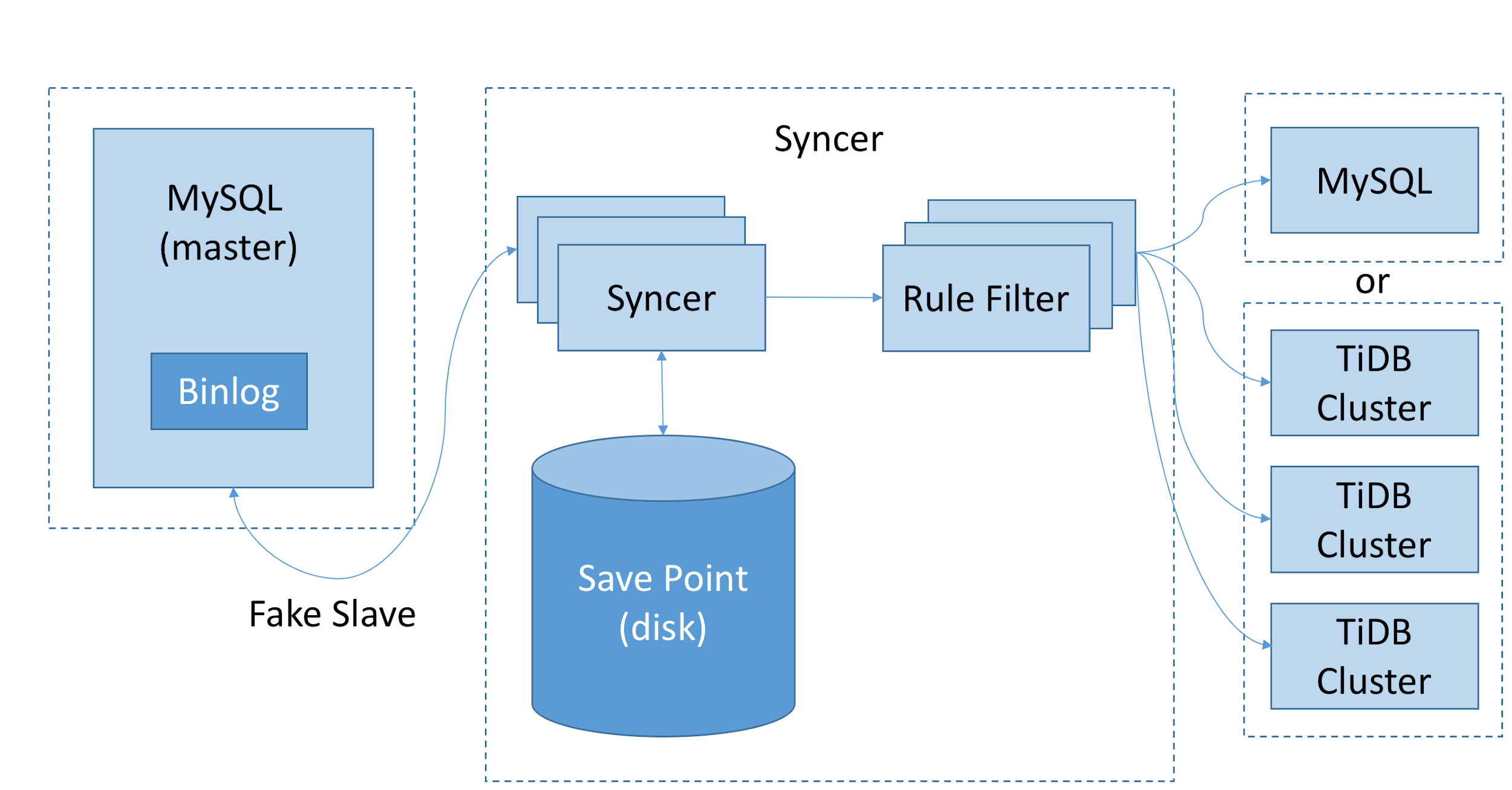
After confirming that TiDB met our test requirement, we did not migrate all the archive jobs to TiDB immediately, because the simulated tests are different from real application scenarios. To further test TiDB, we made workloads that closely reflect production scenarios via Syncer, an enterprise-level migration tool in the TiDB ecosystem.
As shown in the following diagram, Syncer can work as a MySQL slave node to access and parse Binlog in the master and then be applied to TiDB after matching the filter rules. Syncer supports breakpoint resume. It can start multiple Syncer instances to synchronize data from one data source to various targets respectively based on different filter rules. It also supports synchronizing data from multiple data sources to the same target. We chose two high-loaded MySQL archive clusters as the data source and used Syncer to synchronize hundreds of GBs of data during nightly archiving to the TiDB cluster in real time. Our synchronization work lasted about one week without any issues.
Deployment Scale and Design
Around 45 percent of our data archiving workload has been migrated to TiDB and running smoothly. The current archive policy is shown in the diagram below:
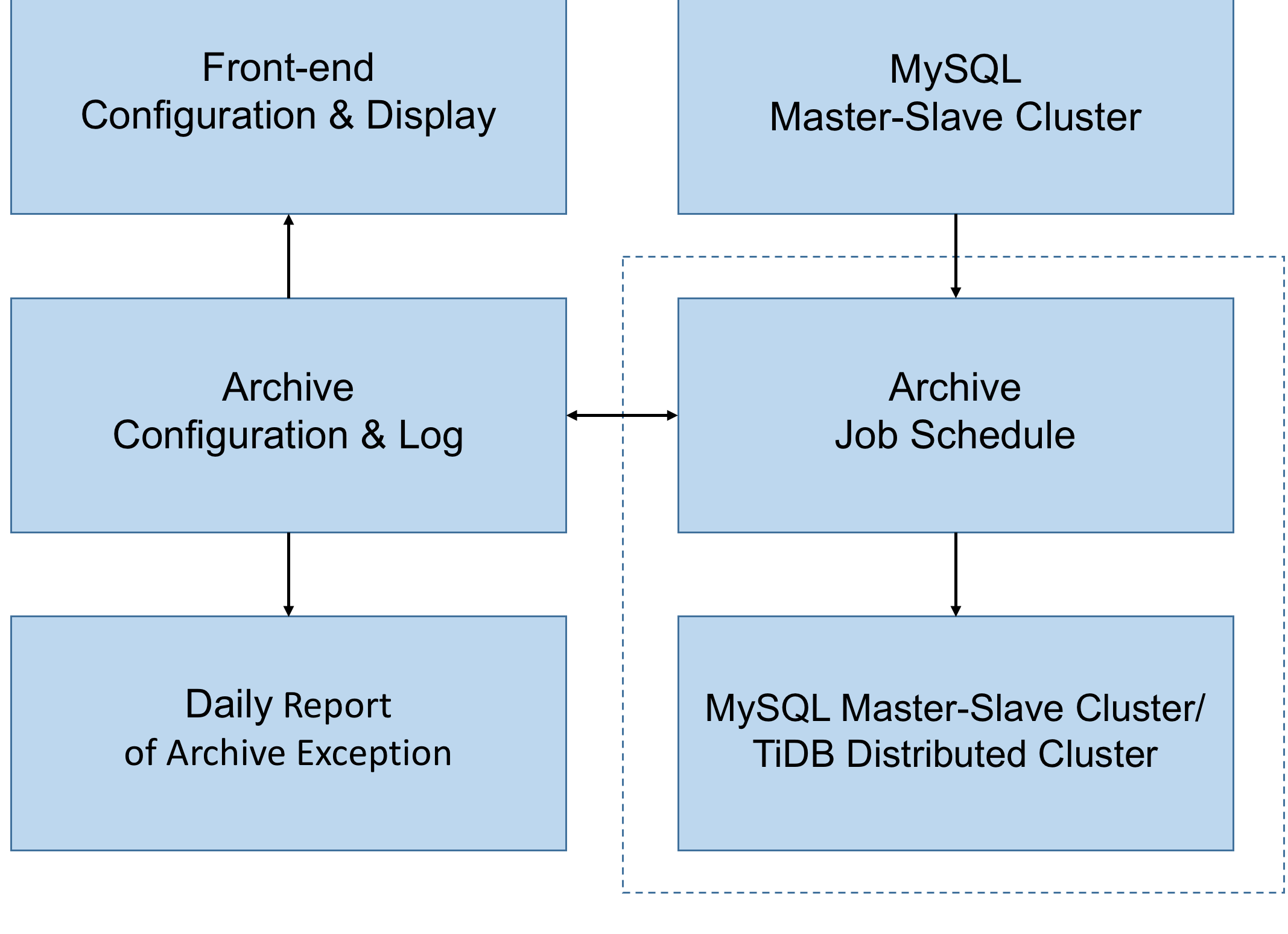
The following two diagrams show the deployment policy and the monitor alert architecture of the TiDB cluster, respectively:
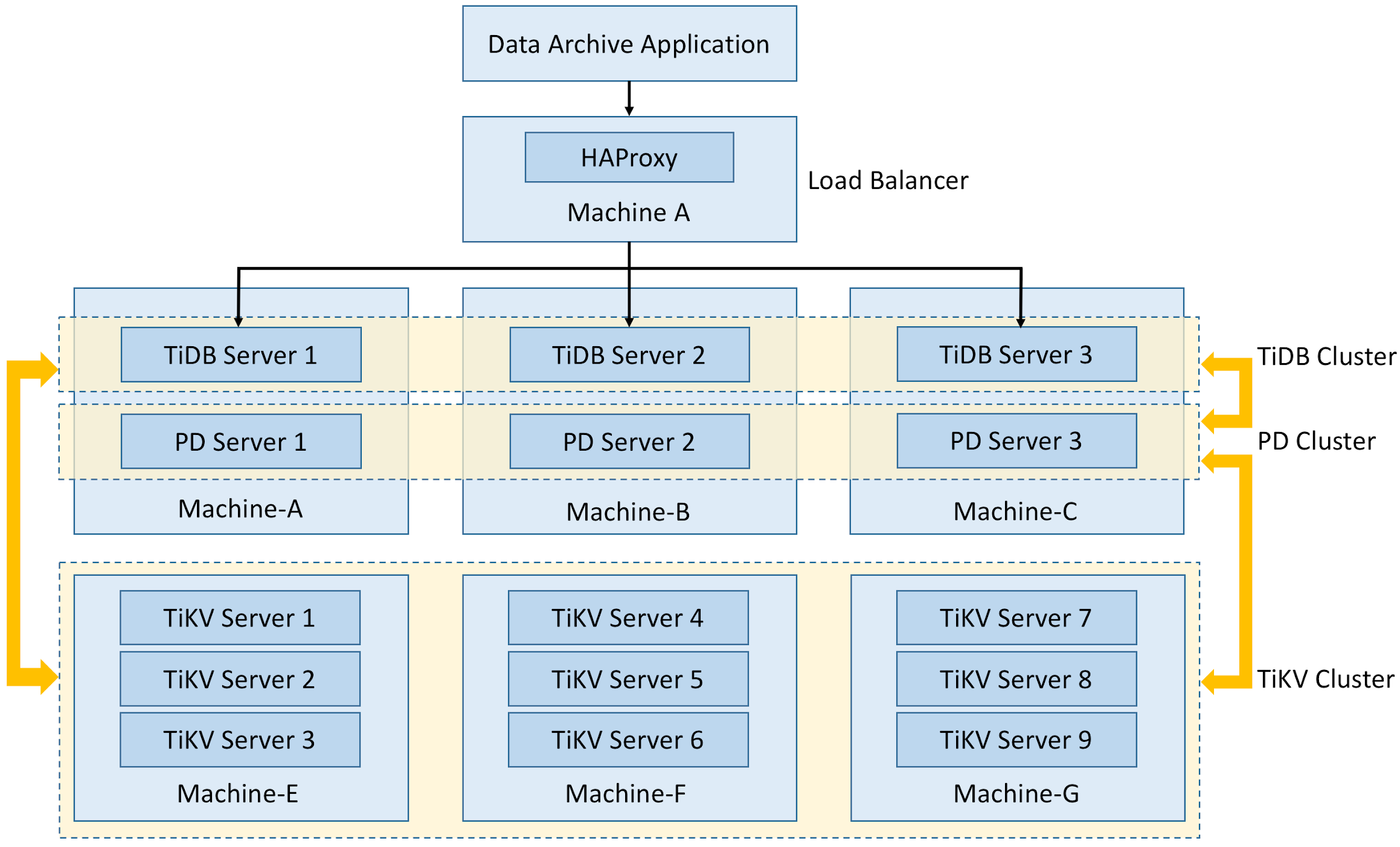
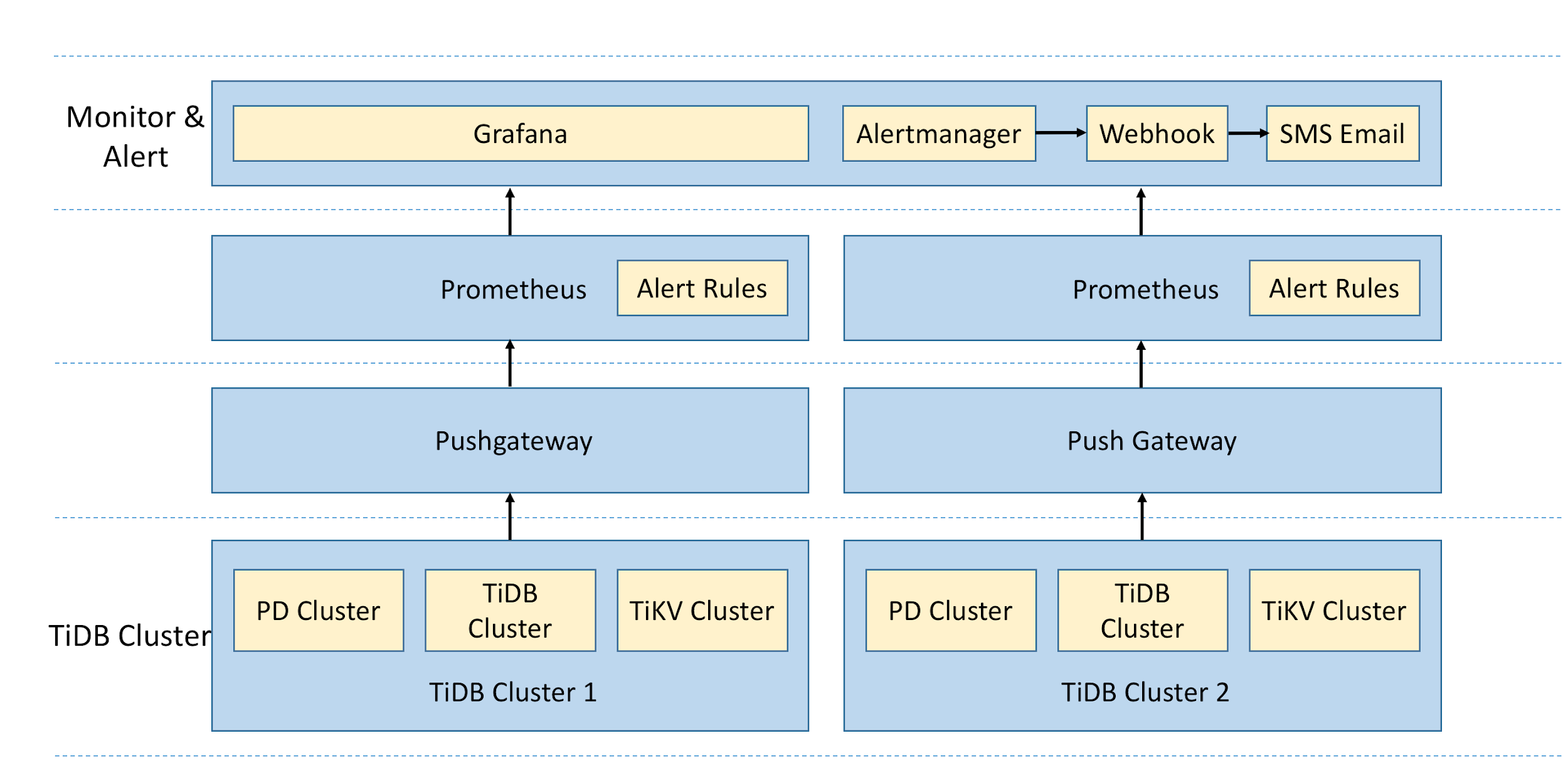
Currently, the archive workload in TiDB has approximately 100 source clusters, dozens of databases, and more than one hundred tables. The data on the whole platform increases by hundreds of millions of lines every day on average, and the daily incremental data reaches hundreds of GBs.
Our TiDB cluster is already storing dozens of TBs, and to add capacity, we just add TiKV nodes without any migration or disruption to the related services. For tables whose schema has changed, the archived tables’ schema dynamically updates. If a node in the cluster fails, the cluster can still be accessed. When the broken node is replaced, data will be synchronized to the new node automatically without manual intervention.
Future Features and Improvement
While testing and using TiDB, we ran into a few issues that the PingCAP team is already working on as future features and improvements. The team is building a DDL concurrent execution feature, which alleviates delay in processing many DDL requests where operations are executed serially. TiDB 2.0 also supports dynamic update of the statistics information and the automatic full Analyze operation, which was not available when we first deployed TiDB, so we had to collect these statistics manually.
Best Practices
In deploying and using TiDB, we have gathered some best practice tips that we’d like to share:
When deploying TiKV on multiple instances, set the parameters for
capacityandblock-cache-sizeproperly; otherwise, disk space overflow and OOM (out of memory) may occur. This is because every Region occupies a small proportion of memory and as more Regions get created, memory usage will rise slightly.When the occupied disk space reaches 80 percent of the set capacity value, the cluster will prevent scheduling data to these nodes but the Write operation continues. Scaling-out process also needs extra temporary space, so users should get ready for scaling ahead of time. We recommend that you prepare for scaling when 60 percent of the disk space is occupied.
Set labels properly when deploying TiKV on multiple instances to distribute data among different data centers, racks, and hosts, and avoid writing multiple replicas on the same machine to guarantee load balancing of nodes.
TiDB has a size limit for a single transaction (each key-value entry can be no more than 6MB), because committing large data using the two-phase commit protocol and creating multiple replicas that data creates a lot of pressure on the system. This problem often occurs when MyDumper is used to export data and MyLoader is used to import the data. It can be overcome by limiting the size of a single Insert operation that MyDumper exports by adding the
-Fparameter.
Conclusion
Our successful use of TiDB and TiKV in Ele.me would not be possible without the timely, professional, and expert-level technical support from the PingCAP team. In the future, we plan to build one or two additional TiDB clusters to hold all our archive jobs, and our use of TiKV will continue to expand inside Ele.me. We may also open-source our Redis Proxy to the community and carry forward the open-source spirit.